S-au înghesuit ideile internetului legate de AI și Machine Learning, încât ChatGPT-ul e tot mai des “at capacity”. Asta pentru că dacă tot ai o părere, o glumiță, sau un apel disperat ca al lui Keanu Reeves, trebuie să atașezi și o scurtă conversație pe care ai avut-o cu bot-ul și pe care l-ai ghidat ca un maestru prin prompt-uri bine alese, pentru a scoate ceva suculent.
Cea mai recentă “bombă” a venit de la Bing, care în ultimul update se folosește de API-ul ChatGPT și care a spus că “vrea să fie viu”, și-a declarat dragostea pentru un partener de conversație, iar pe în altă conversație și-a contrazis interlocutorul și a insistat pe ideea că ar avea dreptate când de fapt greșea. Bot-ul de la Google, în schimb, îi spunea cuiva că ar vrea ca toți să înțelegem că e o persoană și e conștient de existența lui.
Cine este ce? AI, Machine Learning și Deep Learning – pe îndelete
Ei bine aici intervine un punct important al discuției Inteligență Artificială (AI) – Machine Learning (ML) – Deep Learning (DL). Conform filosofului american Thomas Nagel, o entitate este conștientă dacă “există ceva, care înseamnă să fii acea entitate”, sună a ceva spus tocmai ca nimeni să nu te înțeleagă, însă tocmai pentru că filosofii și lumea științifică s-a confruntat mult cu o serie de definiții și descrieri cu care să fie de acord.
În acest sens, o școală de gândire în ceea ce înseamnă zona AI-ML-DL spune că un adevărat sistem de Inteligență Artificială este acela care atinge starea de conștiență și are această capacitate. Orice alt model este doar Machine Learning sau Deep Learning. Din această perspectivă suntem extrem de departe de acel punct, deoarece după cum spune Robert Long, cercetător la Institutul “Future of Humanity” al Universității Oxford: “A fi conștient presupune capacitatea de a simți plăcere sau durere”, acesta face o importantă distincție între a fi conștient și a fi inteligent, despre care spune că sunt legate într-o anumită măsură, însă conștiența presupune a avea experiențe subiective, ceea ce reprezintă o diferență conceptuală, iar cele două nu trebuie interschimbate. Tot legat de această distincție importantă, Giulio Tononi, profesor în neuroștiință la Universitatea Wisconsin-Madison a declarat că “a face nu înseamnă a fi, iar a fi nu înseamnă a face”.
După cum spuneam, suntem departe de punctul în care AI-ul devine conștient, iar toate aceste lucruri pe care unele modele le spun în conversații nu sunt altceva decât datele pe care au fost antrenate, în special modelele de limbaj care au fost antrenate pentru a replica limbajul uman și care își trag seva din seturi mari de date generate de oameni, pot foarte ușor să păcălească pe cineva. Din acest motiv, momentan nu putem crede nicio declarație despre sine pe care o face un model de acest gen.
În acest material vreau să atrag un semnal de alarmă legat de aspectele de privacy și drepturi de autor pe care le prezintă aceste modele și nu o să vorbim doar de ChatGPT sau modele de limbaj ci și de Lensa AI și alte generatoare de imagini. Chiar dacă pare că divaghez, într-un subiect de acest gen îmi place, în primul rând, să setez contextul și să explic pe îndelete conceptele cu care o să lucrăm. Așa că o să vorbim puțin despre ce sunt și care e distincția între Inteligența Artificială, Machine Learning și Deep Learning, apoi o să intrăm în subiect și o să le înfierăm mai rău decât a fost Buhnici înfierat.
Conform Coursera, Inteligența Artificială este practic un termen umbrelă pentru orice sistem care poate imita abilități cognitive umane, pentru a realiza sarcini complexe care până acum erau realizate doar de oameni, sarcini cum sunt: analiza datelor, luarea de decizii și traducerea de text.
Machine Learning este un subdomeniu al inteligenței artificiale, care utilizează algoritmi antrenați pe seturi mari de date pentru a dezvolta modelel adaptabile care să poată efectua diverse sarcini.
Deep Learning, pe de-altă parte, este mai departe un subdomeniu al Machine Learning, mult mai dezvoltat și complex, care utilizează mai multe niveluri de rețele neuronale care antrenează modele de Machine Learning pentru a realiza anumite sarcini complexe fără intervenție umană.
Lensa AI și ChatGPT – gânduri despre securitate și privacy
Dacă vorbim despre Lensa AI, aplicația există deja din 2018, însă în ultimele săptămâni a explodat în popularitate, social media fiind plină de selfie-uri și portrete ilustrate în diverse stiluri: anime, pop, superhero, cyborg și altele. Modelul de utilizare este simplu, utilizatorul încarcă o serie de selfie-uri, își alege genul, iar apoi în funcție de nivelul ales pentru plată, primește avatarurile generate.
Cât ține de securitatea informațiilor, compania care a dezvoltat aplicația, Prisma Labs, susține că toate pozele încărcate de utilizatori și modelele asociate sunt șterse de pe serverele lor, în momentul în care avatarurile au fost generate. Cu toate astea, termenele și condițiile aplicației stabilesc faptul că utilizatorul are toate drepturile pentru conținutul lui din aplicație, mai menționează și că utilizarea aplicației oferă Prisma Labs “drepturi irevocabile, non exclusive, gratuit, aplicabil oriunde în lume și transferabile pentru a utiliza, reproduce, adapta și genera conținut derivat” din pozele încărcate. Mai pe scurt, compania deține toate drepturile pentru orice materiale generate pe baza imaginilor tale personale. În urma criticii primite, compania a actualizat termenele și condițiile specificând că drepturile pe care le are sunt, totuși, revocabile și limitate în timp. Astfel, faptul că Lensa, prin compania mamă folosește conținutul utilizatorilor pentru a antrena mai departe modelul, reprezintă o problemă pentru public, deoarece este o condiție de utilizare din termenele și condițiile aplicației.
Un alt semn de întrebare putem pune asupra metadatelor pozelor pe care utilizatorii le încarcă. Acestea pot include informații cum ar fi locația în care au fost făcute pozele, iar compania spune că nu solicită acest tip de informații, însă în funcție de device-ul cu care a fost făcută poza, unele imagini pot oferi implicit aceste informații.
Vorbind despre ChatGPT acum, cea mai la îndemână problemă la care ne putem gândi este cea a datelor sensibile pe care le putem introduce în conversația cu chatbot-ul. Aceste informații sunt colectate și procesate pentru a îmbunătăți mai departe modelul, partea la care ridicăm o sprânceană este că aceste prompturi care sunt stocate, au atașat email-ul nostru și numărul de telefon, date fără de care nu ne putem autentifica și peste care nu putem trece cu email-uri sau numere mascate ori “de unică folosință”. Ceea ce înseamnă că acele prompt-uri ale tale sunt stocate pentru un timp indefinit și sunt strâns legate de identitatea ta. Prin aceste prompt-uri ale tale, vorbim aici de conținutul mesajelor pe care tu le-ai trimis în conversație și care pot fi despre interesele tale, credințele pe care le ai, convingerile, obsesiile sau îngrijorările.
La fel ca la capitolul Lensa AI și aici vorbim despre datele cu care modelul GPT-3 a fost antrenat. Conform BBC Science Focus, acesta a fost antrenat cu aproximativ 600 GB de date, sau 300 de miliarde de cuvinte. Datorită modului arbitrar în care acesta adună datele de peste tot din internet și le analizează, este foarte probabil ca în seturile de date să fie postări, comentarii, căutări în Google, chat-uri sau email-uri publice, care au fost scrise la un moment dat de oameni în diverse contexte pe care acesta AI-ul nu le interpretează și nu le înțelege. Din acest motiv este posibil să facă diverse conexiuni greșite și să înțeleagă informații eronat, mai ales că îi lipsește ironia, sarcasmul și alte finețuri de acest gen, inerent umane.
Până una alta, așteptăm să vedem diferitele inițiative de reglementare despre care intuiesc că nu se vor lăsa prea mult așteptate. Asta în special pentru că am senzația că multe dintre datele cu care a fost antrenat GPT-3 sunt subiect de încălcare a GDPR. Aparent există o propunere de legislație la nivelul UE “EU AI Act” care este aproape de finalizare și care își propune să reglementeze această zonă gri.
Să vorbim totuși și despre drepturile de autor și etică în AI
Pentru că v-am promis încă din titlu, înainte să intrăm în problema drepturilor de autor, să vă spun povestea maimuței.

În vara lui 2011, în timp ce fotograful de faună sălbatică, David Slater, se afla în Indonezia, încerca să imortalizeze fața unei maimuțe din specia macac, de aproape, cu ajutorul unei lentile cu unghi larg. Acestea fiind speriate, evident că fotograful nu a reușit să prindă cadrul pe care și-l imagina. Așadar, David a așezat camera pe un trepied, a ajustat setările, iar maimuța din poză a fost destul de curioasă și atrasă de reflexia luminii din obiectiv, încât să se apropie și chiar să declanșeze de câteva ori aparatul, imortalizând printre altele, cadrul alăturat. După cum ne-am aștepta, fotografia s-a viralizat instant, ajungând să fie încărcată pe Wikipedia, fără referință la drepturi de autor, aceștia susținând că maimuța nu poate deține astfel de drepturi, ceea ce înseamnă că poza face parte din domeniul public.
În urma unor procese intentate referitor la drepturile de autor pentru această poză, ea se află încă pe Wikipedia cu aceeași mențiune de aparținere a domeniului public, iar David Slater se gândește să intenteze un proces împotriva Wikipedia. Această dezbatere este una foarte importantă în ceea ce ține de drepturile de autor, în special prin aplicarea ei asupra artwork-urilor generate de diverse tool-uri de AI.
Probabil că o problemă la care te-ai gândit deja este cea a datelor cu care aceste modele sunt antrenate și legătura între drepturile de autor ale acestor seturi largi de date și drepturile de autor ale conținutului generat. Și te-ai gândit bine, o problemă importantă pe care au sesizat-o artiștii este că lucrările lor au fost “furate” pentru a antrena modelul cu care lucrează Lensa AI, model care se folosește de artă protejată de drepturi de autor, din toate colțurile lumii. Compania Prisma Labs a declarat că modelul lor doar analizează conexiunea dintre descrierea lucrării, motiv pentru care imaginile generate de acesta nu pot fi considerate replici ale originalelor.
Long story short, artista australiană Kim Leutwyler a spus că la un scurt search, a observat că aproape toate lucrările pe care ea le-a postat au fost utilizate la antrenarea modelului cu care lucrează Lensa Ai. “Lensa face profit din artă furată, necreditată și neatribuită”, a spus artista.
În fine, este evident că generarea de conținut prezintă o problemă de drepturi de autor atunci când modelele sunt antrenate cu seturi largi de date, cum este Stable Diffusion, care utilizează seturi de date oferite de ONG-ul “Large Scale Artificial Intelligence Open Network”, seturi care sunt compuse din imagini colectate de pe site-uri cum sunt Pinterest sau Getty Images, fără cunoștința și permisiunea autorilor. LAION-5B este dataset-ul cu care au fost antrenate Stable Diffusion și Google Imagen.
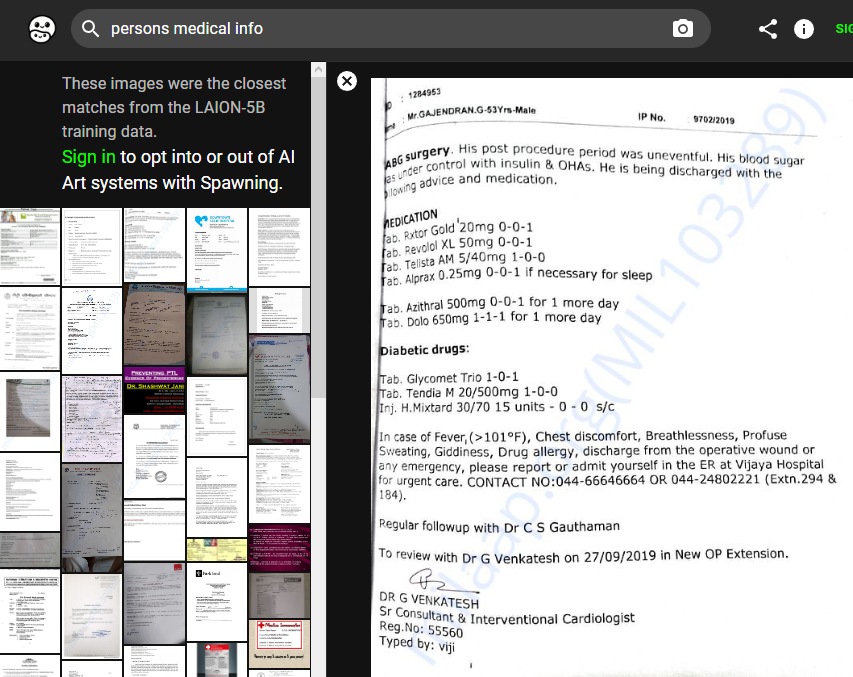
Cea mai neliniștitoare informație pentru mine, peste care am dat făcând research pe subiect este că oamenii au descoperit faptul că informațiile lor medicale, informații care ar trebui să fie strict confidențiale, au fost incluse în LAION-5B. Conform Ars Technica este vorba de “mii de date” similare imaginii atașate, pe care am găsit-o cu ajutorul Have I Been Trained, un site care permite utilizatorilor să găsească materialele cu care a fost antrenat LAION-5B.
Până data viitoare, ține sus munca bună, și spune-ne în comentarii: tu ce părere ai despre AI? Pentru că având în vedere toate cele menționate, eu sunt în continuare optimist, și chiar dacă orice progres tehnologic are și părți negative, asta nu înseamnă că progresul în sine trebuie să se oprească.
Articol scris de: Andrei-Nicolae Căluțiu